Understanding Speculative Decoding
I had read about speculative decoding (some papers also refer to it as speculative sampling) almost a year ago and understood the general idea at the time. But I happened to revisit the concept recently and found myself wondering how is it that we are able to get a speed-up in token generation even though there are two models running at the same time. So I decided to dive deeper and understand the intricacies.
The Challenge: Slow Token Generation in Large LLMs
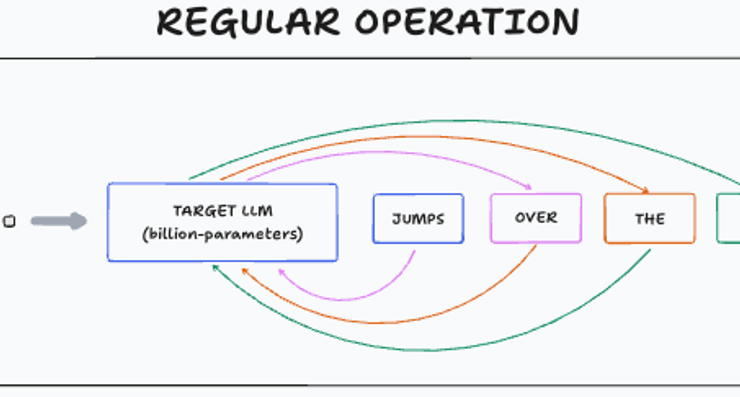
Let’s take it from the top - the main challenge with large language models (think of something like a Chinchilla model with 70 billion parameters) is that the process of generating new tokens is sequential and time-consuming. Let me explain it with a simple example:
Imagine you have an input token sequence like “The quick brown fox.” which is the user prompt for which you want to get a completion from the LLM.
Initial Pass: This entire sequence (“The quick brown fox”) is fed into the LLM (our 70-billion-parameter model).
First Token Generation: The LLM processes this input and generates the next predicted token, for example, “jumps.”
Feedback Loop: This newly generated token (“jumps”) is then appended to the original sequence, making it “The quick brown fox jumps.”
Next Pass: This entire new sequence is fed back into the LLM, and the process repeats. The LLM then generates “over.”
Continuous Loop: This continues for every single token in the sequence.
As you can see from the diagram, this means that for every token you want to generate, you have to perform a full forward pass through this massive neural network. In our example with four tokens generated (“jumps,” “over,” “the”, “dog”), that’s four forward passes through a 70-billion-parameter model. This typically takes around 14 milliseconds per token generation. When you’re generating long pieces of text, these milliseconds add up quickly, leading to noticeable delays.
The Solution: Speculative Decoding – A Hybrid Approach
The goal of speculative decoding is to find a clever way to accelerate this process. The core idea is to introduce a second, much smaller LLM into the mix, which they call the draft model. This draft model is orders of magnitude smaller – think millions of parameters, not billions. And it doesn’t even need to be a LLM at all, it is only a mechanism to generate possible completion tokens. See an example that achieves this by sampling draft tokens from the input prompt itself - especially for use-cases like “Chat with PDF”, “Summarize this document” where it’s likely that many tokens from the input will likely feature in the output.
But let’s consider the case of the draft LLM now and understand how it works. This is what I found most interesting where I came across Teacher-Forcing that I did not know before! Assume the same input as before but this time there is the draft model first -
Draft Token Generation (Small LLM): Instead of immediately sending the sequence to the large LLM, you first send it to the smaller draft LLM. Using our example, “The quick brown fox” goes into the draft LLM. It generates “jumps.” This “jumps” is added to the sequence (“The quick brown fox jumps”). This new sequence goes back into the draft LLM, generating “over.” And so on.
While the process works in the same way as for the larger LLM, it is significantly faster because the draft model has lesser number of parameters. As indicated in the diagram, for these four tokens, it involves four forward passes through a million-parameter network, taking about 1.8 milliseconds per token generation. This is already a huge win in terms of speed for initial predictions!
Verification (Large LLM with “Teacher Forcing”): Now, this is the really clever part. Once the draft LLM has generated a few speculative tokens (let’s say “jumps,” “over,” “the”, “dog”), you don’t send them one by one to the large LLM for confirmation. Instead, you send the entire sequence of original input plus the drafted tokens (“The quick brown fox jumps over the dog”) to the large target LLM in a single go. But here’s the trick: The large LLM isn’t asked to predict the next token in the traditional sense. Instead, it’s put into a special mode referred to as “teacher forcing”.
What is Teacher Forcing? An LLM is trained to predict the next token when given a sequence. But at the time of training, the data is always passed in the form of batches. For a given sentence, all the tokens are available to the LLM. The training involves getting the LLM to predict the probability of the next token - in a sliding window fashion. For each window, the LLM generates the probability for the next token, then it is compared with the ground truth to determine the error and perform back-propagation so that the weights can be adjusted. It actually does this for all windows in the same batch, at the same time and then aggregates the error. So when the LLM operates in this mode - it actually generates the probability of all tokens in a given sentence in one step.
Speculative decoding leverages this training mode. When the large LLM receives the input sequence plus the draft tokens, it’s essentially put into this “teacher forcing” mode. It then calculates the token probabilities for each of the draft tokens simultaneously.
Accept or Reject: So now you have the probabilities that the large LLM would have given to the draft tokens and you decide whether the draft tokens are accepted or not based on certain criteria -
- If the large LLM “agrees” with the draft tokens, they are accepted as correct.
- If a drafted token’s probability is too low (meaning the large LLM would likely have generated something different), that token and all subsequent drafted tokens from that batch are rejected.
- The large LLM then takes over and generates the correct token from that point onward, reverting to the regular, slower generation process for a few steps until a new batch of draft tokens can be generated.
The Payoff: Speed and Accuracy
The beauty of this method lies in its efficiency. By performing just one forward pass through the large LLM to verify multiple draft tokens (which is much faster than generating them one by one), you significantly reduce the computational load on the most resource-intensive part of the process. The paper claims that this results in a speed-up of 2 to 2.5 times compared to regular operation, while maintaining the high accuracy of the larger model. This happens because, statistically, the smaller draft model is often good enough to predict the next few tokens correctly, allowing the large model to simply verify them in a highly efficient, parallel manner.
The part that tripped me up was how the number of forward passes through the large neural network is being reduced and that’s where understanding the Teacher Forcing concept really helped. I tried to write it down as a way to help me remember it myself. Let me know if you have other intuitions or if you find something incorrect in how I explained it.