The EU Is Trying to Regulate AI. But First, It Has to Define It.
Regulating fast-moving technology is never easy, especially when it’s still evolving. But just because it’s difficult doesn’t mean it isn’t necessary. In fact, it’s often in these moments - when the lines are still being drawn and the stakes are rising - that thoughtful regulation matters most.
AI is often compared to electricity - a fundamental technology that impacts and changes the way a lot of things work. Therefore, it might be interesting to observe how regulation worked then. In its early days, electrical infrastructure was fragmented, chaotic, and often dangerous. Competing standards, poor-quality components, and ad hoc installations led to fires, electrocutions, and a lack of interoperability. The turning point came when it started being treated as infrastructure that is regulated. Governments and standards bodies stepped in: they defined safety protocols, required testing and certification, and made sure that grid infrastructure in one city could connect reliably to others.
We could take a similar approach with general-purpose AI. Instead of trying to regulate every use case as it arises, we can establish standards and safety tests that models must meet before being widely deployed. Just as we don’t question whether an electrical socket is safe before plugging in, we should be able to trust that the models powering AI systems have been evaluated against known risks and calibrated to prevent known harms.
The EU AI Act is an ambitious attempt to move in this direction. The European Commission has launched a public consultation to Clarify the Scope of the General-purpose AI Rules in the AI Act. As someone residing in the EU and using AI to build products, I think it’s important to engage meaningfully in this dialogue. I tried to read and understand the general AI Act and more specifically the proposed guidelines that this consultation is about. This is my effort to articulate my thoughts and encourage feedback to make sure I have the correct understanding. Technologies like AI evolve in months, not decades and the challenges in regulating it are real. But so is the opportunity to help shape a paradigm that can guide innovation without stifling it.
Defining General-Purpose AI: Proxy or Principle?
One of the central and most important aspects in the guidelines is the definition of a general-purpose AI model. The guidelines attempt to define general-purpose AI models based on the amount of computational resources, measured in Floating Point Operations (FLOPs), used during model training. However, this proxy definition may not fully capture the scope and capabilities of such models.
This is a pragmatic choice, but also a blunt instrument. Compute usage doesn’t always correlate neatly with generality. Newer techniques like distillation allow smaller models, trained with fewer resources, to exhibit broad capabilities.
I noticed a smaller nitpick. The following statement - a model that can generate text and/or images is a general-purpose AI model. This seems to exclude models that are trained to generate raw audio, video, or what are now commonly referred to as multi-modal models. Based on the current guidelines, models that can generate raw audio, video, or what are referred to as multi-modal models may not be considered general-purpose AI models, although they clearly possess broad capabilities. The definition of general-purpose AI models should be expanded to explicitly include such multi-modal models.
In the same vein, the guidelines also state that narrow-purpose models that are used for transcription or code generation do not qualify as general-purpose. There has been some indication in recent papers (e.g. Deepseek-R1) that models trained for code-generation tasks also seem to get better at creative writing and solving math (so-called emergent behaviors). This suggests that such models, despite their initial narrow focus, may in fact possess general-purpose abilities that go beyond their original intended use case.
I believe that a more robust approach might involve developing an internal benchmark suite, given the reasons above. This would be the AI equivalent of a “standards lab” that tests models across a range of reasoning, safety, and generality dimensions. Let’s call it EU-bench! Just as we test circuit boxes for voltage tolerances and overload resistance, we should test models for robustness, reliability, and behavioral boundaries. And this can be a combination of automated tests with human-in-the-loop red-teaming and validations.
Navigating the Downstream Modifier and fine-tuning maze
Let’s consider what the guidelines state on the topic of a downstream modifier.
This implies that if you fine-tune an existing model, use more than one-third of the training compute that was used to train it originally, and place it on the market, then this model will also be considered a general-purpose AI model.
In addition, the guidelines also take into consideration which entity does the fine-tuning. From the guidelines -
I understand that this clause is meant to exclude minor versions of the same model, fine-tuned by the same entity as long as they use less than a third of the compute required for the original model. The fine-tuning threshold of a third of the source model remains the same for everyone, but linking that with an entity seemed to be confusing to me.
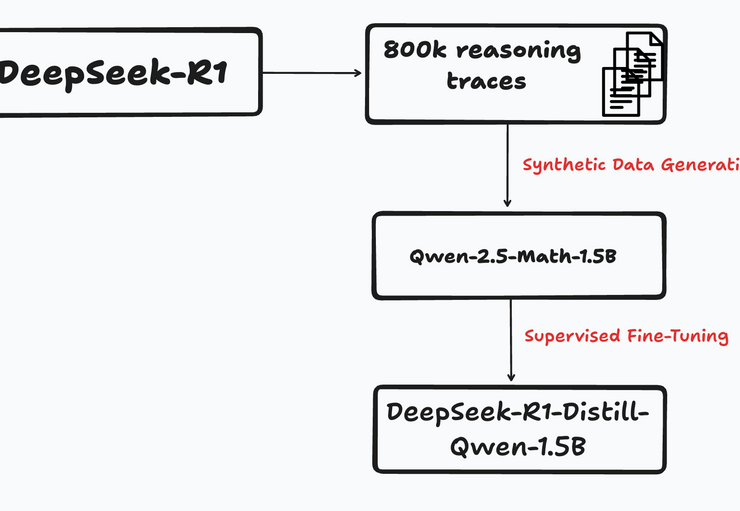
As a practitioner, I tried to think about how one would estimate whether a fine-tuned model would be considered general-purpose or not. I picked the DeepSeek-R1-Distill-Qwen-1.5B model that was released by DeepSeek as part of their R1 paper as my example. The model was trained in the following manner -
First, researchers used the DeepSeek-R1 model to generate synthetic data (800k reasoning traces). Then, they used this data to fine-tune a small base model - Qwen-2.5-Math-1.5B using Supervised Fine-Tuning. The end result is DeepSeek-R1-Distill-Qwen-1.5B which shows reasonable performance across a range of tasks and comparable to Claude-Sonnet-3.5 and GPT-4o. Based on that, one might consider that as general-purpose.
But let’s try to calculate and check if fine-tuning this model actually utilized more than a third of the training compute utilized by the base model. I made some very rough approximations (with the help of ChatGPT):
Base model: Qwen2.5-Math-1.5B. It was trained on 18 trillion tokens. Using the formula provided in the guidelines (inspired by the Chinchilla paper), we arrive at 1.62 × 10²³ FLOPs, which definitely qualifies as a general-purpose AI model.
Generation of synthetic data: the guidelines say that synthetic data generation must also be considered when estimating training compute. There are 800k reasoning traces generated from the large DeepSeek-R1 MoE model. Using certain assumptions for how much compute it might take to generate a single token, the size of the DeepSeek model, number of prompts etc., I arrived at the number of 5.92 × 10¹⁹ FLOPs. This is where I’m least confident and where the guidelines also don’t provide any input.
Supervised Fine-tuning: is performed using the 800k observations for 2 epochs on a 1.5B model. This translates to roughly 1.44 × 10¹⁹ FLOPs.
Final result: The fine-tuning costs and cost of synthetic data generation combined still put us below the one-third threshold. Therefore, this specific model would not qualify as a general-purpose AI model as per the guidelines. This would likely be the case for the large Llama-70B fine-tunes as well.
Conclusion: I found the process of estimating the training compute to be tedious and likely open to judgment. For instance, if one just used the 800k dataset (or any other dataset) from HuggingFace instead of generating it themselves, would the costs still have to be considered? I also assume that the cost of training DeepSeek-R1 itself does not play a role in this exercise but I’m not 100% sure.
As model architectures, training methodologies, and techniques like model merging become more prominent, the process of arriving at this will likely become more cumbersome. My argument is that instead of using fixed thresholds, a combination of factors and measures might work better. Let’s consider compute, but also usage scope, deployment or usage context, and an audit of actual capabilities (with something like EU-bench).
Placing on the Market and the Open-Source Dilemma
The guidelines broadly define “placing on the market,” including uploading a model to a public repository. This is understandable as a precautionary step, but it also raises concerns. In the open-source world, sharing models for research and experimentation is a key part of how progress happens. Requiring compliance just for uploading a model, even when no commercial activity is involved, risks chilling open collaboration.
To be fair, the Act includes exemptions for open-source models that are fully accessible, modifiable, and non-commercial. But these exemptions disappear if the model is deemed to pose systemic risk. However, that term remains vague and currently is qualified only by the use of more compute. A more nuanced framework might allow for a tiered exemption system, where limited research deployment triggers minimal obligations, and more expansive or commercial use scales up accordingly.
Notification Requirements: Regulating Intent?
One surprising inclusion in the guidelines is the requirement to notify the AI Office when a provider anticipates crossing the systemic risk compute threshold, even before training begins. The rationale is that pre-training plans involve upfront resource allocation, and so this intent can be flagged in advance.
But this seems premature. Not every planned model ends up being viable (reference recent news reports on the Llama behemoth model). Some experiments might be abandoned. Others are never released because it doesn’t make sense for business reasons. Requiring notification for intent alone risks creating overhead and discouraging experimentation. A more reasonable approach might be to require notification at the point of model deployment or release, once systemic impact can be more accurately assessed.
Toward a Practical, Principles-Based Framework
It’s always easier to point out problems than to propose solutions. However, the challenges in the current draft of the guidelines offer an opportunity to think constructively about what effective regulation could look like.
A few starting points that come to my mind:
Develop a standardized evaluation suite (EU-bench) to assess model capabilities, robustness, and risk profiles, akin to electrical safety testing.
Use a portfolio of indicators, not just compute thresholds, to assess general-purpose status and systemic risk.
Create a tiered regulatory structure where obligations scale with deployment scope and demonstrated capability, not just training budget.
I have come across an alternate view that suggests not regulating models but rather the applications of these models (AI systems) or doing so at the organization level. I think each of those options also come with challenges, and since the idea of a general-purpose AI model has now been enshrined, it will be hard to move away from that. If electricity taught us anything, it’s that infrastructure doesn’t regulate itself. The goal should be to build systems we can trust because they are responsibly and intelligently governed.